![[42Seoul] Push_Swap : 정렬 알고리즘 구현](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FtpWsH%2Fbtq9ngn3vux%2FAAAAAAAAAAAAAAAAAAAAAF7XeCAhcXVievT_-EQ8Usm-PSkIEQzKOhv1djkxeZ8L%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DyUhnVOf3TmGVpSyVpWdhr5PG3nU%253D)
1. 게임 규칙

이 게임은 a와 b라는 이름의 두 개의 스택으로 이루어져 있고 게임은 다음과 같이 시작한다.
- a는 서로 중복되지 않는 음수 혹은 양수인 난수들을 포함한다.
- b는 비어있다.
이 게임의 목표는 스택 a에 오름차순으로 수를 정렬하는 것이다.
정렬을 위해 다음 명령어들을 수행할 수 있다.
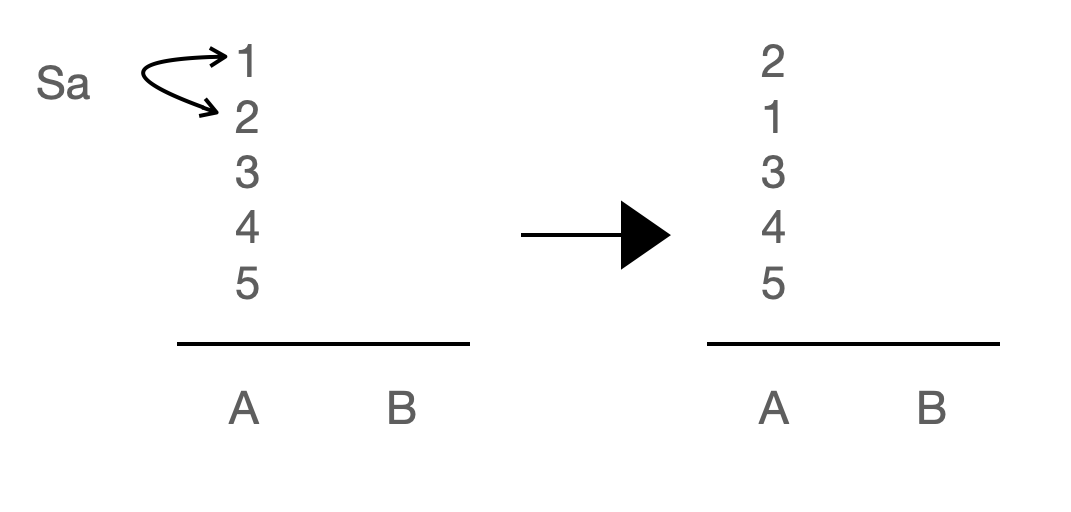
| 명령어 | 기능 |
| sa : swap a | 스택 a의 가장 위에 있는 두 원소의 위치를 서로 바꾼다. |
| sb : swap b | 스택 b의 가장 위에 있는 두 원소의 위치를 서로 바꾼다. |
| ss : sa + sb | sa와 sb를 동시에 실행한다. |

| 명령어 | 기능 |
| pa : push a | 스택 b에서 가장 위(탑)에 있는 원소를 가져와서, 스택 a의 맨 위(탑)에 넣는다. 스택 b가 비어 있으면 아무 것도 하지 않는다. |
| pb : push b | 스택 a에서 가장 위(탑)에 있는 원소를 가져와서, 스택 b의 맨 위(탑)에 넣는다. 스택 a가 비어있으면 아무 것도 하지 않는다. |

| 명령어 | 기능 |
| ra : rotate a | 스택 a의 모든 원소들을 위로 1 인덱스 만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다. |
| rb : rotate b | 스택 b의 모든 원소들을 위로 1 인덱스 만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다. |
| rr : ra + rb | ra와 rb를 동시에 실행한다. |
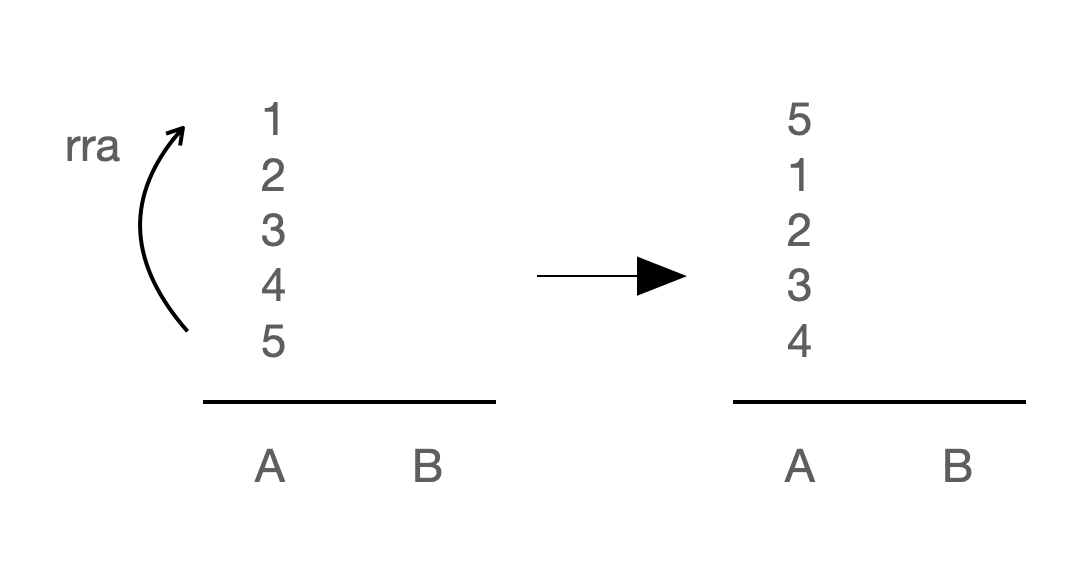
| 명령어 | 기능 |
| rra : reverse rotate a | 스택 a의 모든 원소들을 아래로 1 인덱스 만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다. |
| rrb : reverse rotate b | 스택 b의 모든 원소들을 아래로 1 인덱스 만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다. |
| rrr : rra + rrb | rra와 rrb를 동시에 실행한다. |
2. 스택 구현
연결리스트? 배열? 원형?
어떤 방식으로 두개의 스택과 명령어를 수행할 수 있는 구조를 만들까 고민을 하다 몇개의 숫자가 들어오는지 사이즈는 정해져 있기에 주어진 사이즈만큼의 배열을 만들고 구조체를 이용해 top과 bottom 값을 계속 바꿔주고 저장하는 구조체 배열로 구현을 해보았다.
명령어는 양방향으로 변경이 가능하기에 stack 보다는 deque와 가장 가깝다 생각했고 c++의 deque로 구현해보았다.
typedef struct s_dq {
int *arr;
int top; // top 인덱스 번호를 저장
int bottom; // bottom 인덱스 번호를 저장
} t_dq;
3. pivot을 이용한 정렬
숫자가 적을때는 단순 비교를 이용해 정렬하면 되지만 정렬해야 할 수가 많아 질 수록 연산의 수가 기하급수적으로 늘어난다.
정렬해야할 범위 수를 줄여보자해서 pivot을 기준으로 범위를 나누어주었다.
그럼 피봇(기준 값)은 어떻게 정해줄까?
뒤섞인 배열을 따로 저장해두어 기존에 있는 Quick Sort로 정렬을 해주었다. 짠!

이제 정렬된 배열에서 기준이 될 피봇값을 가져올 것이다.
이 배열을 보고 몇개의 큰 덩어리(chunk)로 나누어 주고 그 안에서 정렬을 시행하는 것이다.
덩어리는 100개의 인자가 들어왔을 때 기준으로 5개의 chunk로 나누어 주었다.

-------------------
chunk1 : 0 ~ 19
chunk2 : 20 ~ 39
chunk3 : 40 ~ 59
chunk4 : 60 ~ 79
chunk5 : 80 ~ 99
-------------------
4. Chunk 나누기

1. chunk범위 기준으로 stack A를 rotate a 를 하며 탐색하여
해당 범위 안에 있는 값이라면 push b를 해준다.
2. stack B의 top으로 옮겨진 chunk의 값을 절반으로 또 나누어
stack B의 아래로 내려준다. (한번의 탐색으로 2개의 청크를 나눌 수 있는 방법)
3. 총 5번의 탐색으로 stack B에는 총 10개의 chunk를 나누어져있다.
4. stack A 에는 가장 큰 수를 담고 있는 chunkd의 가장 큰 값과 작은 값만 남겨두었다.
(앞으로 양방향 탐색을 할 것이기 때문이다.)
5. 양방향 탐색
위의 과정이 끝나고 나면 이제 stack A에는 가장 큰 chunk의 가장 큰 값과 작은 값만 남게된다.
이제 이 값을 big, small이라 부르겠다.
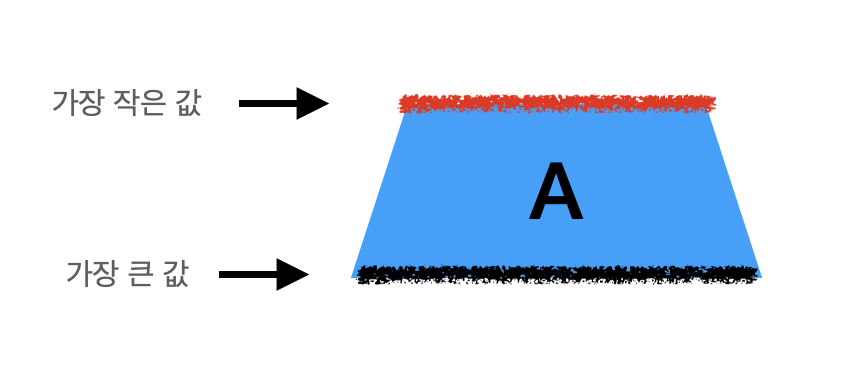

이 stack은 top과 bottom, 양쪽에서 값을 꺼내고 넣을 수 있기 때문에 나누어진 stack B의 양쪽에서 big의 이전 인덱스, small의 다음 인덱스를 찾아 가장 적은 움직임으로 stack A에 옮길 수 있는 값을 넣어줄 것이다.

그렇게 순차적으로 넣은 값은 하나의 chunk가 다 옮겨질때 까지 계속 되며 이렇게 위아래로 나누어져 쌓여진 stack A를 rra(reverse rotate a)를 이용해 하나로 합쳐준다.
이렇게 모든 chunk가 다 옮겨지면 정렬이 완료된다.
6. 최적화
좀 더 연산의 수를 줄이기 위해 적용한 최적화 방법이다.
1. chunk를 나누어 stack B로 보내줄 때 조건이 맞다면 rr 처럼 두번의 연산을 하나로 줄일 수 있게 하였다.
2. 2개의 값(big - 1, small + 1)만 탐색하지 않고 그 다음에 들어갈 값(big - 2, small + 2)도 함께 총 4개의 인덱스를 탐색해주었고 +- 2의 인덱스라면 swap을 해주어 순서를 변경해 연산을 줄여보았다.
3. 인자가 500개가 들어왔을 때에는 8개의 chunk로 나누어주어야 가장 빠르며 그 이상 나누게 되면 탐색할때 stack A를 rotate 하는 비용이 더 들게 된다.

'42Seoul' 카테고리의 다른 글
| [42Seoul] Philosophers : 뮤텍스와 세마포어 (0) | 2021.08.14 |
|---|---|
| [42 Seoul] Minitalk : signal 함수로 IPC(Inter-Process Communication) 구현 (0) | 2021.07.02 |
| [42Seoul] ft_server (Docker + LEMP) (0) | 2021.03.01 |
| [42Seoul] ft_printf - 나의 printf 구현하기 (0) | 2021.02.06 |
| [42Seoul] Netwhat - 네트워크 및 시스템 관리 (0) | 2021.01.23 |